Database management system imp
(click on read more)
1. Relational Database Design
- View
- To restrict data access.
- To make complex query easy.
- To provide data independencies.
- To represents different views of same data.
- Syntax
- Example
- Introduction to the PL/pgSQL Exception clause
When an error occurs in a block, PostgreSQL will abort the execution of the block and also the surrounding transaction.
To recover from the error, you can use the exception clause in the begin...end block.
*The following illustrates the syntax of the exception clause:
<<label>>
declare
begin
statements;
exception
when condition [or condition...] then
handle_exception;
[when condition [or condition...] then
handle_exception;]
[when others then
handle_other_exceptions;
]
end;
- Handling exception examples
We’ll use the film table from the sample database for the demonstration.
Film table
1) Handling no_data_found exception example
The following example issues an error because the film with id 2000 does not exist.
do
$$
declare
rec record;
v_film_id int = 2000;
begin
-- select a film
select film_id, title
into strict rec
from film
where film_id = v_film_id;
end;
$$
language plpgsql;
Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)
Output:
ERROR: query returned no rows
CONTEXT: PL/pgSQL function inline_code_block line 6 at SQL statement
SQL state: P0002
Trigger:
An SQL trigger allows you to specify SQL actions that should be executed automatically when a specific event occurs in the database. For example, you can use a trigger to automatically update a record in one table whenever a record is inserted into another table.
Triggers are, in fact, written to be executed in response to any of the following events −
- A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)A
- database definition (DDL) statement (CREATE, ALTER, or DROP).
- A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
- Generating some derived column values automatically
- Enforcing referential integrity
- Event logging and storing information on table access
- Auditing
- Synchronous replication of tables
- Imposing security authorizations
- Preventing invalid transactions
- Example
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Old salary: ' || :OLD.salary);
dbms_output.put_line('New salary: ' || :NEW.salary);
dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/
When the above code is executed at the SQL prompt, it produces the following results
Trigger created.
Cursors
A cursor is a pointer to this context area. PL/SQL controls the context area through a cursor. A cursor holds the rows (one or more) returned by a SQL statement. The set of rows the cursor holds is referred to as the active set.
You can name a cursor so that it could be referred to in a program to fetch and process the rows returned by the SQL statement, one at a time. There are two types of cursors −
- Implicit cursors
- Explicit cursors
Explicit Cursors
- Declaring the cursor for initializing the memory
- Opening the cursor for allocating the memory
- Fetching the cursor for retrieving the data
- Closing the cursor to release the allocated memory
2. Transaction concepts
A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
Let’s take an example of a simple transaction. Suppose a bank employee transfers Rs 500 from A's account to B's account. This very simple and small transaction involves several low-level tasks.
A’s Account
Open_Account(A)
Old_Balance = A.balance
New_Balance = Old_Balance - 500
A.balance = New_Balance
Close_Account(A)
B’s Account
Open_Account(B)
Old_Balance = B.balance
New_Balance = Old_Balance + 500
B.balance = New_Balance
Close_Account(B)
- ACID Properties
A transaction is a very small unit of a program and it may contain several lowlevel tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
- Atomicity − This property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
- Consistency − The database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
- Durability − The database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
- Isolation − In a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transactions are interleaved with some other transaction.
Schedule − A chronological execution sequence of a transaction is called a schedule. A schedule can have many transactions in it, each comprising of a number of instructions/tasks.
Types of schedule

Serial Schedules:
Schedules in which the transactions are executed non-interleaved, i.e., a serial schedule is one in which no transaction starts until a running transaction has ended are called serial schedules.
Example: Consider the following schedule involving two transactions T1 and T2.
T1 T2
R(A)
W(A)
R(B)
W(B)
R(A)
R(B)
where R(A) denotes that a read operation is performed on some data item ‘A’
This is a serial schedule since the transactions perform serially in the order T1 —> T2
Non-Serial Schedule:
This is a type of Scheduling where the operations of multiple transactions are interleaved. This might lead to a rise in the concurrency problem. The transactions are executed in a non-serial manner, keeping the end result correct and same as the serial schedule. Unlike the serial schedule where one transaction must wait for another to complete all its operation, in the non-serial schedule, the other transaction proceeds without waiting for the previous transaction to complete. This sort of schedule does not provide any benefit of the concurrent transaction. It can be of two types namely, Serializable and Non-Serializable Schedule.
The Non-Serial Schedule can be divided further into Serializable and Non-Serializable.
Serializable:
This is used to maintain the consistency of the database. It is mainly used in the Non-Serial scheduling to verify whether the scheduling will lead to any inconsistency or not. On the other hand, a serial schedule does not need the serializability because it follows a transaction only when the previous transaction is complete. The non-serial schedule is said to be in a serializable schedule only when it is equivalent to the serial schedules, for an n number of transactions. Since concurrency is allowed in this case thus, multiple transactions can execute concurrently. A serializable schedule helps in improving both resource utilization and CPU throughput. These are of two types:
1.Conflict Serializable:
A schedule is called conflict serializable if it can be transformed into a serial schedule by swapping non-conflicting operations. Two operations are said to be conflicting if all conditions satisfy:
They belong to different transactions
They operate on the same data item
At Least one of them is a write operation
2. View Serializable:
A Schedule is called view serializable if it is view equal to a serial schedule (no overlapping transactions). A conflict schedule is a view serializable but if the serializability contains blind writes, then the view serializable does not conflict serializable.
Non-Serializable:
The non-serializable schedule is divided into two types, Recoverable and Non-recoverable Schedule.
1.Recoverable Schedule:
Schedules in which transactions commit only after all transactions whose changes they read commit are called recoverable schedules. In other words, if some transaction Tj is reading value updated or written by some other transaction Ti, then the commit of Tj must occur after the commit of Ti.
Example – Consider the following schedule involving two transactions T1 and T2.
T1 T2
R(A)
W(A)
W(A)
R(A)
commit
commit
This is a recoverable schedule since T1 commits before T2, that makes the value read by T2 correct.
There can be three types of recoverable schedule:
a.Cascading Schedule:
Also called Avoids cascading aborts/rollbacks (ACA). When there is a failure in one transaction and this leads to the rolling back or aborting other dependent transactions, then such scheduling is referred to as Cascading rollback or cascading abort.
Example:

b.Cascadeless Schedule:
Schedules in which transactions read values only after all transactions whose changes they are going to read commit are called cascadeless schedules. Avoids that a single transaction abort leads to a series of transaction rollbacks. A strategy to prevent cascading aborts is to disallow a transaction from reading uncommitted changes from another transaction in the same schedule.
In other words, if some transaction Tj wants to read value updated or written by some other transaction Ti, then the commit of Tj must read it after the commit of Ti.
Example: Consider the following schedule involving two transactions T1 and T2.
T1 T2
R(A)
W(A)
W(A)
commit
R(A)
commit
This schedule is cascadeless. Since the updated value of A is read by T2 only after the updating transaction i.e. T1 commits.
c.Strict Schedule:
A schedule is strict if for any two transactions Ti, Tj, if a write operation of Ti precedes a conflicting operation of Tj (either read or write), then the commit or abort event of Ti also precedes that conflicting operation of Tj.
In other words, Tj can read or write updated or written value of Ti only after Ti commits/aborts.
Example: Consider the following schedule involving two transactions T1 and T2.
T1 T2
R(A)
R(A)
W(A)
commit
W(A)
R(A)
commit
This is a strict schedule since T2 reads and writes A which is written by T1 only after the commit of T1.
2.Non-Recoverable Schedule:
Example: Consider the following schedule involving two transactions T1 and T2.
T1 T2
R(A)
W(A)
W(A)
R(A)
commit
abort
T2 read the value of A written by T1, and committed. T1 later aborted, therefore the value read by T2 is wrong, but since T2 committed, this schedule is non-recoverable.
Serial Schedule − It is a schedule in which transactions are aligned in such a way that one transaction is executed first. When the first transaction completes its cycle, then the next transaction is executed. Transactions are ordered one after the other. This type of schedule is called a serial schedule, as transactions are executed in a serial manner.
Equivalence Schedules
An equivalence schedule can be of the following types −
Result Equivalence
If two schedules produce the same result after execution, they are said to be result equivalent. They may yield the same result for some value and different results for another set of values. That's why this equivalence is not generally considered significant.
View Equivalence
Two schedules would be view equivalence if the transactions in both the schedules perform similar actions in a similar manner.
For example −
- If T reads the initial data in S1, then it also reads the initial data in S2.
- If T reads the value written by J in S1, then it also reads the value written by J in S2.
- If T performs the final write on the data value in S1, then it also performs the final write on the data value in S2.
Conflict Equivalence
Two schedules would be conflicting if they have the following properties −
- Both belong to separate transactions.
- Both accesses the same data item.
- At least one of them is "write" operation.
Two schedules having multiple transactions with conflicting operations are said to be conflict equivalent if and only if −
- Both the schedules contain the same set of Transactions.
- The order of conflicting pairs of operation is maintained in both the schedules.
Note − View equivalent schedules are view serializable and conflict equivalent schedules are conflict serializable. All conflict serializable schedules are view serializable too.
States of Transactions
A transaction in a database can be in one of the following states −
Transaction States
- Active − In this state, the transaction is being executed. This is the initial state of every transaction.
- Partially Committed − When a transaction executes its final operation, it is said to be in a partially committed state.
- Failed − A transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
- Aborted − If any of the checks fails and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are called aborted. The database recovery module can select one of the two operations after a transaction aborts −
- Re-start the transaction
- Kill the transaction
- Committed − If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.

3. Concurrency Control
Concurrency Control in DBMS
Executing a single transaction at a time will increase the waiting time of the other transactions which may result in delay in the overall execution. Hence for increasing the overall throughput and efficiency of the system, several transactions are executed.
Concurrently control is a very important concept of DBMS which ensures the simultaneous execution or manipulation of data by several processes or user without resulting in data inconsistency.
Concurrency control provides a procedure that is able to control concurrent execution of the operations in the database.
- Concurrency Control Problems
There are several problems that arise when numerous transactions are executed simultaneously in a random manner. The database transaction consist of two major operations “Read” and “Write”. It is very important to manage these operations in the concurrent execution of the transactions in order to maintain the consistency of the data.
- Dirty Read Problem(Write-Read conflict)
Dirty read problem occurs when one transaction updates an item but due to some unconditional events that transaction fails but before the transaction performs rollback, some other transaction reads the updated value. Thus creates an inconsistency in the database. Dirty read problem comes under the scenario of Write-Read conflict between the transactions in the database
The lost update problem can be illustrated with the below scenario between two transactions T1 and T2.
Transaction T1 modifies a database record without committing the changes.
T2 reads the uncommitted data changed by T1
T1 performs rollback
T2 has already read the uncommitted data of T1 which is no longer valid, thus creating inconsistency in the database.
- Lost Update Problem
Lost update problem occurs when two or more transactions modify the same data, resulting in the update being overwritten or lost by another transaction. The lost update problem can be illustrated with the below scenario between two transactions T1 and T2.
T1 reads the value of an item from the database.
T2 starts and reads the same database item.
T1 updates the value of that data and performs a commit.
T2 updates the same data item based on its initial read and performs commit.
This results in the modification of T1 gets lost by the T2’s write which causes a lost update problem in the database.
- Advantages of Concurrency
In general, concurrency means, that more than one transaction can work on a system. The advantages of a concurrent system are:
Waiting Time: It means if a process is in a ready state but still the process does not get the system to get execute is called waiting time. So, concurrency leads to less waiting time.
Response Time: The time wasted in getting the response from the cpu for the first time, is called response time. So, concurrency leads to less Response Time.
Resource Utilization: The amount of Resource utilization in a particular system is called Resource Utilization. Multiple transactions can run parallel in a system. So, concurrency leads to more Resource Utilization.
Efficiency: The amount of output produced in comparison to given input is called efficiency. So, Concurrency leads to more Efficiency.
- Disadvantages of Concurrency
Overhead: Implementing concurrency control requires additional overhead, such as acquiring and releasing locks on database objects. This overhead can lead to slower performance and increased resource consumption, particularly in systems with high levels of concurrency.
Deadlocks: Deadlocks can occur when two or more transactions are waiting for each other to release resources, causing a circular dependency that can prevent any of the transactions from completing. Deadlocks can be difficult to detect and resolve, and can result in reduced throughput and increased latency.
Reduced concurrency: Concurrency control can limit the number of users or applications that can access the database simultaneously. This can lead to reduced concurrency and slower performance in systems with high levels of concurrency.
Complexity: Implementing concurrency control can be complex, particularly in distributed systems or in systems with complex transactional logic. This complexity can lead to increased development and maintenance costs.
Inconsistency: In some cases, concurrency control can lead to inconsistencies in the database. For example, a transaction that is rolled back may leave the database in an inconsistent state, or a long-running transaction may cause other transactions to wait for extended periods, leading to data staleness and reduced accuracy.
- Concurrency Control Techniques in DBMS:
The concurrency control techniques in DBMS that are used to avoid problems related to concurrency control in DBMS in order to maintain consistency and serializability, also known as Protocols are as follow:-
- Lock-Based Protocol:-
In order to avoid issues related to inconsistency, one of the foremost requirements is to achieve isolation between all the transactions and to achieve that, locking is done on transactions on account of any read/write operation.
- The two variant locks used in the lock-based protocol are
- Shared Lock
- Exclusive Lock
Shared Lock:
It locks the write operations but enables the read operation to take place hence they go by the name, read-only locks. They are denoted by ‘S’ in a transaction.
Exclusive Lock:
For certain data, It locks both the read and write operations in a transaction and is denoted by ‘E’.
Four types of lock-based protocols are:-
1. Simplistic Lock Protocol:-
It locks all the operations in the process, the moment when data is about to be updated and unlocks the operations afterwards.
2. Pre-claiming lock protocol:-
Before enabling locks, all the operations are analyzed and the ones that fall in the checklist of the problem-causing operations are locked only in case all the locks are available and the transaction is performed effectively else rollback is performed.
3. Two-Phase Locking:-
This technique is performed in three stages.
Asks for the availability of locks
On acquiring all locks, transaction releases first lock
Rest of the locks are released one by one after each operation.
4. Strict Two-Phase Locking:-
Slight modification in Two-phase Locking where the locks are not released after each operation but once all the operations are done executing for good and the commit is triggered, the collective release of locks is performed.
- Time-Based Protocol:-
All the transactions are tagged with a timestamp which denotes the time when the first and latest read and write operations were performed on them. Timestamp Ordering Protocol is put in place where the timestamp of operations is responsible for ensuring serializability. It holds three timestamps, one for operation and the other two for Read and Writing time. (R & W)
Let’s suppose A is our transaction and G is data and we want to perform a write operation on data.
If Timestamp(A) < R(G) which indicates the Timestamp on the operation is lesser than the time when the data was read last, in such a scenario, rollback will be performed as a result of the data that was read later than the timestamp of the transaction.
Also If Timestamp(A) < W(G) which indicates the Timestamp on the operation is lesser than the time when the data was written last, in such a scenario, rollback will be performed as a result of the data that was written later than the timestamp of the transaction.
On the contrary, when we want to perform a read operation on data then,
If Timestamp(A) < W(G) which indicates the Timestamp on the transaction is lesser than the time when the data was written last, in such a scenario, rollback will be performed as a result of the data that was written later than the timestamp of the transaction.
And if Timestamp(A) >= W(G) then the operation will be executed because the Timestamp of the transaction is greater than the last time the data was written which means that the serializability will be maintained.
- Validation-Based Protocol
This protocol is divided into three phases which are as follows:-
1. Read Phase:- All the data modifications inside the transaction are stored in a local buffer and reused when needed in later operations.
2. Validation Phase:- Validation is performed to ensure that the actual values can replace what is already pre-existent in the buffer.
Validation Test: Tests are performed on transactions in concurrency control in DBMS on the basis of their execution time such that Timestamp(A) < Timestamp(B). The set of rules are:-
Start(B) > End(A) – When transaction A is done executing, the start of transaction B is done. In this manner, the serializability is not affected.
Validate(B) > End(A) > Start(B) – It states that the validation is performed after the end of transaction A if A ends executing after the onset of Transaction B, as one of the effective concurrency control techniques in DBMS.
3. Write Phase:- If the validation phase is performed well and good, the values are copied otherwise a rollback is performed.
- FAQs Related to Concurrency Control in DBMS:
1. What is concurrency control in DBMS?
Ans. To increase throughput and remove waiting time and errors, the measures or techniques applied are known as concurrency control in DBMS.
2. What are protocols in DBMS?
Ans. Protocols can be defined as rules or more precisely, the concurrency control techniques in DBMS to avoid unnecessary errors in transactions.
3. What is serializability relative to concurrency control in DBMS?
Ans. The order of correct execution of operations stands for serializability.
4.Crash Recovery
DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
- Failure Classification
- Transaction failure
Reasons for a transaction failure could be −
- Logical errors − Where a transaction cannot complete because it has some code error or any internal error condition.
- System errors − Where the database system itself terminates an active transaction because the DBMS is not able to execute it, or it has to stop because of some system condition. For example, in case of deadlock or resource unavailability, the system aborts an active transaction.
2. System Crash
There are problems − external to the system − that may cause the system to stop abruptly and cause the system to crash. For example, interruptions in power supply may cause the failure of underlying hardware or software failure.Examples may include operating system errors.
3. Disk Failure
In early days of technology evolution, it was a common problem where hard-disk drives or storage drives used to fail frequently.Disk failures include formation of bad sectors, unreachability to the disk, disk head crash or any other failure, which destroys all or a part of disk storage.
- Recovery and Atomicity
- When a DBMS recovers from a crash, it should maintain the following −
- It should check the states of all the transactions, which were being executed.
- A transaction may be in the middle of some operation; the DBMS must ensure the atomicity of the transaction in this case.
- It should check whether the transaction can be completed now or it needs to be rolled back.
- No transactions would be allowed to leave the DBMS in an inconsistent state.
- There are two types of techniques, which can help a DBMS in recovering as well as maintaining the atomicity of a transaction −
- Maintaining the logs of each transaction, and writing them onto some stable storage before actually modifying the database.
- Maintaining shadow paging, where the changes are done on a volatile memory, and later, the actual database is updated.
- Log-based Recovery
- Log-based recovery works as follows −
- The log file is kept on a stable storage media.
- When a transaction enters the system and starts execution, it writes a log about it.
- When the transaction modifies an item X, it write logs as follows −
- It reads Tn has changed the value of X, from V1 to V2.
- When the transaction finishes, it logs −
- The database can be modified using two approaches −
- Deferred database modification − All logs are written on to the stable storage and the database is updated when a transaction commits.
- Immediate database modification − Each log follows an actual database modification. That is, the database is modified immediately after every operation.
- Recovery with Concurrent Transactions
Checkpoint
Recovery

- The recovery system reads the logs backwards from the end to the last checkpoint.
- It maintains two lists, an undo-list and a redo-list.
- If the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, it puts the transaction in the redo-list.
- If the recovery system sees a log with <Tn, Start> but no commit or abort log found, it puts the transaction in undo-list.
5. Database security
- The database administrator (DBA) is the central authority for managing a database system. The DBA’s responsibilities include granting privileges to users who need to use the system and classifying users and data in accordance with the policy of the organization. The DBA has a DBA account in the DBMS, sometimes called a system or superuser account, which provides powerful capabilities that are not made available to regular database accounts and users.
- DBA-privileged commands include commands for granting and revoking privileges to individual accounts, users, or user groups and for performing the following types of actions:
- The following are the main control measures are used to provide security of data in databases:
- Authentication :
- Access Control :
- Inference Control :
- Flow Control :
- Database Security applying Statistical Method :
- Encryption :
6. Database System Architecture
- User Interface − Users can communicate with the database system using the user interface. It could take the form of a web-based interface, a GUI, or a command-line interface. Users may submit queries, enter data, and see query results or reports via the user interface.
- Query Processor − The query processor executes and optimizes SQL queries after receiving them from users or applications. In order to get the required data and carry out any necessary activities, it analyses the query, chooses the most effective execution plan and communicates with other components. In order to reduce resource consumption and boost speed, the query processor makes sure that queries are processed as effectively as possible.
- Storage Manager − Managing the actual physical storage of data on discs or other storage media is the responsibility of the storage manager. To read and write data, it communicates with the file system or storage subsystem. To facilitate data access and guarantee data integrity, the storage manager manages data archiving, retrieval, and indexin
- Buffer Manager − Data transfer between memory and disc storage is controlled by the buffer manager, an important component. It reduces disc I/O operations and boosts efficiency by using a buffer cache to keep frequently used data pages in memory. The buffer manager makes sure that data caching and replacement procedures are effective in order to maximize memory consumption.
- Transactions Manager − Database transactions' atomicity, consistency, isolation, and durability are all guaranteed by the transaction manager. To maintain data integrity and concurrency management, it maintains concurrent access to the data, takes care of transaction execution, and enforces transaction isolation levels.
- Data Dictionary − The metadata regarding the database schema and objects are stored in the data dictionary, sometimes referred to as the metadata repository. It includes details on various database structures, including tables, columns, data types, constraints, indexes, and more. The DBMS uses the data dictionary to verify queries, uphold data integrity, and offer details on the database structure
- Concurrency Control − Multiple transactions can access and edit the database simultaneously without resulting in inconsistent data thanks to concurrency control methods. To regulate concurrent access and preserve data integrity, methods including locking, timestamp ordering, and multi-version concurrency control (MVCC) are utilized.
- Backup and recovery − In order to safeguard against data loss and guarantee data availability, database systems must have backup and recovery processes. In the case of system failures or data corruption, recovery procedures are employed to restore the database to a consistent condition. Regular backups are performed to create copies of the database.
- Unit test sample question paper click on link ( open in drive)👍
1 mark question
c) What is Transaction?
d) What are different types of loops available in PL/pgSQL?
e) Which are states of transaction?
f) What is Cursor?
2 mark question
a) Explain advantages of PL/SQL.
b) Explain Consistency and Isolation property
c) Explain Structure of PL/pgSQL code block.
d) Explain Conditional statements in PL/pgSQL.
e) Define terms: a) Implicit Cursor b) Explicit Cursor
1) Explain declaring function parameters in PL/pgSQL.
5 mark question
a) Explain ACID Properties of transaction
b) Explain concept of View in detail with example
. c) Explain States of Transaction in detail.
Answer.click Next page
What are ACID Properties in DBMS?
Transactions refer to the single logical units of work that access and (possibly) modify the contents present in any given database. We can access the transactions using the read and write operations.
If we want to maintain database consistency, then certain properties need to be followed in the transactions known as the ACID (Atomicity, Consistency, Isolation, Durability) properties. Let us discuss them in detail.

A – Atomicity
Atomicity means that an entire transaction either takes place all at once or it doesn’t occur at all. It means that there’s no midway. The transactions can never occur partially. Every transaction can be considered as a single unit, and they either run to completion or do not get executed at all. We have the following two operations here:
—Commit: In case a transaction commits, the changes made are visible to us. Thus, atomicity is also called the ‘All or nothing rule’.
—Abort: In case a transaction aborts, the changes made to the database are not visible to us.
Consider this transaction T that consists of T1 and T2: Transfering 100 from account A to account B.

In case the transaction fails when the T1 is completed but the T2 is not completed (say, after write(A) but before write(B)), then the amount has been deducted from A but not added to B. This would result in a database state that is inconsistent. Thus, the transaction has to be executed in its entirety in order to ensure the correctness of the database state.
C – Consistency
Consistency means that we have to maintain the integrity constraints so that any given database stays consistent both before and after a transaction. If we refer to the example discussed above, then we have to maintain the total amount, both before and after the transaction.
Total after T occurs = 400 + 300 = 700.
Total before T occurs = 500 + 200 = 700.
Thus, the given database is consistent. Here, an inconsistency would occur when T1 completes, but then the T2 fails. As a result, the T would remain incomplete.
I – Isolation
Isolation ensures the occurrence of multiple transactions concurrently without a database state leading to a state of inconsistency. A transaction occurs independently, i.e. without any interference. Any changes that occur in any particular transaction would NOT be ever visible to the other transactions unless and until this particular change in this transaction has been committed or written to the memory.
The property of isolation ensures that when we execute the transactions concurrently, it will result in such a state that’s equivalent to the achieved state that was serially executed in a particular order.
Let A = 500, B = 500
Let us consider two transactions here- T and T”

Suppose that T has been executed here till Read(B) and then T’’ starts. As a result, the interleaving of operations would take place. And due to this, T’’ reads the correct value of A but incorrect value of B.
T’’: (X+B = 50, 000+500=50, 500)
Thus, the sum computed here is not consistent with the sum that is obtained at the end of the transaction:
T: (A+B = 50, 000 + 450 = 50, 450).
It results in the inconsistency of a database due to the loss of a total of 50 units. The transactions must, thus, take place in isolation. Also, the changes must only be visible after we have made them on the main memory.
D – Durability
The durability property states that once the execution of a transaction is completed, the modifications and updates on the database gets written on and stored in the disk. These persist even after the occurrence of a system failure. Such updates become permanent and get stored in non-volatile memory. Thus, the effects of this transaction are never lost.
Uses of ACID Properties
In totality, the ACID properties of transactions provide a mechanism in DBMS to ensure the consistency and correctness of any database. It ensures consistency in a way that every transaction acts as a group of operations acting as single units, produces consistent results, operates in an isolated manner from all the other operations, and makes durably stored updates. These ensure the integrity of data in any given database......
What Does View Mean?
A view is a subset of a database that is generated from a user query and gets stored as a permanent object.
View
Views in SQL are the virtual tables that do not really exist like the tables of the database. These Views are created by SQL statements that join one or more tables. The views contain rows and columns. We can CREATE VIEW by selecting the fields from one or more tables of the database. We can also Update and Drop the views according to our requirements.
Create SQL View
We can create View using the CREATE VIEW statement. A View can be created using a single table or multiple tables.
The basic Syntax for creating VIEW:
CREATE VIEW view_name AS
SELECT column1, column2, column3...
FROM table_name
WHERE [condition];Examples: Suppose we have two tables. First, the Customer_Details Table which has attributes as Customer_id, Name, Address, Age .

Second, the Customer_Order Table which has attributes as Customer_id, Name, Product, Date .
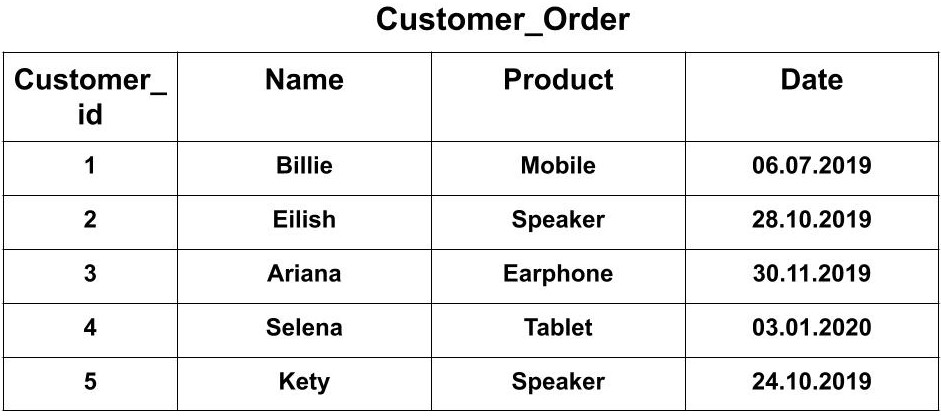
- Creating a view from a single Table:
Query
CREATE VIEW Customer_view AS
SELECT Customer_id, Name, Address
FROM Customer_Details
WHERE Address = "Miami";The above CREATE VIEW statement would create a virtual table based on the result of the SELECT statement. Now, you can query the SQL VIEW as follows to see the output:
SELECT * FROM Customer_view;In reality, there is no table named Customer_view. It's just a view that we are using.
Output
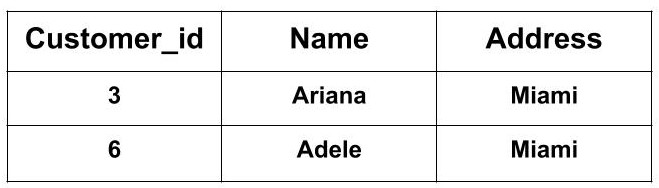
Types Of Transaction States
There are six major types of Transaction states which are as given below- Active state
- Partially committed state
- Committed state
- Failed state
- Aborted state
- Terminated state
1. Active State
When the instructions of the transaction are executing then the transaction is in active state.
In case of execution of all instruction of transaction, Transaction can go to “partially committed state” otherwise go to “failed state” from active state.
.2. Partially Committed State
After the execution of all instruction of a transaction, the transaction enters into a partially committed state from active state.
At this stage, Still Changes are possible in transaction because all the changes made by the transaction are still store in the buffer of main memory.
3. Committed State
Committed state permanently store all changes made by the transaction into the database
Now, the transaction is consider as fully committed.
4. Failed State
Note: At this stage, Transaction cannot go to “partially committed state” or “active state” .
5. Aborted State
As we know failed state can never be resuming but it is possible to restart the failed transaction. To restart the failed transaction Rollback method comes into picture.
When we rollback (restart) the failed transaction the all the changes made by that transaction earlier have to be undone.
6. Terminated State
This is the last stage of transaction in its life cycle.I
f any transaction comes from “Aborted state” or “committed state” then that transaction is terminated and get ready to execute the new transactions.
Structure of PL/pgSQL
PL/pgSQL is a block-structured language. The complete text of a function definition must be a block. A block is defined as:
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END;
Each declaration and each statement within a block is terminated by a semicolon.
All key words and identifiers can be written in mixed upper and lower case. Identifiers are implicitly converted to lower-case unless double-quoted.
There are two types of comments in PL/pgSQL. A double dash (--) starts a comment that extends to the end of the line. A /* starts a block comment that extends to the next occurrence of */. Block comments cannot be nested, but double dash comments can be enclosed into a block comment and a double dash can hide the block comment delimiters /* and */.
Any statement in the statement section of a block can be a subblock. Subblocks can be used for logical grouping or to localize variables to a small group of statements.
The variables declared in the declarations section preceding a block are initialized to their default values every time the block is entered, not only once per function call. For example:
CREATE FUNCTION somefunc() RETURNS integer AS '
DECLARE
quantity integer := 30;
BEGIN
RAISE NOTICE ''Quantity here is %'', quantity; -- Quantity here is 30
quantity := 50;
--
-- Create a subblock
--
DECLARE
quantity integer := 80;
BEGIN
RAISE NOTICE ''Quantity here is %'', quantity; -- Quantity here is 80
END;
RAISE NOTICE ''Quantity here is %'', quantity; -- Quantity here is 50
RETURN quantity;
END;
' LANGUAGE plpgsql;
It is important not to confuse the use of BEGIN/END for grouping statements in PL/pgSQL with the database commands for transaction control. PL/pgSQL's BEGIN/END are only for grouping; they do not start or end a transaction. Functions and trigger procedures are always executed within a transaction established by an outer query --- they cannot start or commit transactions, since PostgreSQL does not have nested transactions.
What are Cursors in SQL?
Cursors are user-defined iterative variables that allow us to access the query results or the results of the stored procedure.
Cursors are objects we define using a Declare statement and take a Select statement as the parameter.
1. Explicit Cursor
An explicit cursor requires a declaration by the user by the use of the SELECT statement. It goes over each record but only a single row is processed at a time. Once the reading of one row is complete it moves to another row.
2. Implicit Cursor
An implicit cursor is put internally by SQL whenever the user runs any DML query. Also, implicit cursors are made for one single row of the database.

No comments:
Post a Comment